LLMO
Optimierung für Large Language Models
LLMO (Large Language Model Optimization) bezeichnet die gezielte Aufbereitung von Inhalten für generative KI-Systeme wie ChatGPT, Googles AI Mode oder Perplexity. Das Ziel dieser noch jungen Disziplin ist es, Marken und Inhalte in den Antworten solcher Sprachmodelle sichtbar zu machen. Damit ist die Bedeutung von LLMO vergleichbar mit der Rolle von SEO im klassischen Suchmaschinenmarketing.

Das Wichtigste zu LLMO & GAIO für Dich zusammengefasst:
- LLMO optimiert Inhalte gezielt für generative KI-Systeme wie ChatGPT, Gemini oder Claude, um deren Antworten aktiv zu beeinflussen.
- Ziel ist es, dass Marken und Inhalte in generierten Antworten direkt genannt, zitiert oder als Quelle verlinkt werden.
- Da KI-Trainingsdaten statisch sind, liegt der Fokus auf der Optimierung für Modelle mit Zugriff auf Echtzeitdaten (Retrieval Augmented Generation).
- KI-Assistenten könnten klassische Suchmaschinen ersetzen; wer hier nicht präsent ist, verliert seine digitale Sichtbarkeit.
- Der Einfluss klassischer SEO hängt davon ab, welche Quellen (etwa Bing und Google) das Sprachmodell nutzt.
- In der LLMO wichtige Faktoren sind etwa eine natürliche Sprache, strukturierte Inhalte mit kurzen und präzisen Antworten sowie Erwähnungen der eigenen Marke im Internet.
- URLs spielen für LLM kaum eine Rolle. Wichtiger sind die Qualität und das Format des Inhalts.
Was ist LLMO?
LLMO (Large Language Model Optimization) bezeichnet die gezielte Optimierung von Inhalten für große Sprachmodelle wie ChatGPT, Perplexity oder Claude. Im Gegensatz zur klassischen SEO, die sich unter anderem auf Keywords und Backlinks fokussiert, zielt LLMO darauf ab, Inhalte maschinell verständlich, kontextreich und strukturiert aufzubereiten. Die Optimierung erfolgt somit nicht mehr primär für Suchalgorithmen, sondern für Modelle, die Texte semantisch analysieren und in neue Zusammenhänge setzen. Dazu gehört auch Gemini, welches die Basis für Googles AI Overviews und den Google AI Mode bildet.
Die wesentlichen Maßnahmen umfassen unter anderem:
- Klare Strukturen und natürliche Sprache anstelle von Keyword-Fokussierung.
- Aufbau von für LLMs relevanten Vertrauens- und Autoritätssignalen.
- Optimierung auf Kontextbasis zur direkten Beantwortung komplexer Anfragen.
Der wirksamste Hebel liegt dabei nicht in der schwer beeinflussbaren Manipulation von Trainingsdaten, sondern in der Phase der Antwortgenerierung durch Retrieval Augmented Generation (RAG) – die Kombination von Trainingsdaten mit aktuellen Informationen aus dem Netz. Da viele Modelle in Echtzeit auf externe Quellen zugreifen, lässt sich die Sichtbarkeit in KI-Antworten durch gezielten Content und eine klare Informationsarchitektur direkt beeinflussen.
Was ist ein Large Language Model?
Ein LLM ist ein komplexes KI-Sprachmodell, dessen Fähigkeiten auf der Auswertung großer Textmengen basieren. Solche Modelle – prominente Vertreter sind etwa Gemini oder ChatGPT – beherrschen die Interpretation sowie Generierung menschlicher Sprache umfassend und verändern die Art und Weise der Informationssuche fundamental.
Die Ziele der Large Language Model Optimization
Der zentrale Zweck der LLMO ist es, die Präsenz von Marken und Inhalten in den Antworten generativer KI-Systeme zu maximieren. Modelle wie ChatGPT, Perplexity oder Gemini nutzen vielfältige Quellen, um präzise Ergebnisse zu liefern. Large Language Model Optimization kann dazu beitragen, dass Dein Content dabei öfter genannt, zitiert oder verlinkt wird.
Dabei werden zwei Primärziele verfolgt:
- Referenzierung als Quelle: Durch strukturierte und themenrelevante Inhalte wird die eigene Website als vertrauenswürdige Informationsquelle positioniert, die in KI-Antworten verlinkt wird.
- Erwähnung von Marken, Produkten oder Dienstleistungen: Auch ohne direkten Link kann es ein Vorteil sein, wenn Deine Marke oder Dein Angebot in generierten Texten erwähnt oder empfohlen werden.
Damit dies gelingt, verfolgt die LLMO verschiedene Teilziele:
- Höhere Sichtbarkeit in KI-Antworten: Die Marke oder Webseite wird Teil der Antwortlogik von KI-Systemen. Das kann Aufmerksamkeit und Traffic erzeugen.
- Aufbau von Autorität: Die regelmäßige Verwendung Deiner Inhalte als Referenz etabliert Dich langfristig als thematische Autorität im digitalen Wettbewerb.
- Optimierte Nutzererfahrung: Gut strukturierte Inhalte helfen der KI bei der Informationsverarbeitung und verbessern die Lesbarkeit auch für die Nutzer. Je besser die Inhalte aufbereitet sind, desto eher liefern sie schnelle und hilfreiche Antworten. Das kann sich auch positiv auf klassische Suchmaschinenrankings auswirken.
LLMO, GEO und Co.: Worin bestehen die Unterschiede?
Derzeit gibt es noch keine einheitliche Terminologie für diese neue Disziplin. Neben LLMO werden auch Begriffe wie GEO (Generative Engine Optimization), AIO (Artificial Intelligence Optimization) oder AEO (Answer Engine Optimization) verwendet. Sie alle beschreiben Ansätze, Inhalte für generative KI-Systeme sichtbarer zu machen, unterscheiden sich aber mitunter in ihrer exakten Zielsetzung. Teilweise können sie jedoch auch als Unterbegriffe von LLMO verstanden werden.
- KI SEO: KI SEO steht als Dachbegriff für die Evolution der Suchmaschinenoptimierung unter dem Einfluss künstlicher Intelligenz. Es beschreibt die Transformation klassischer Strategien, um den neuen Anforderungen moderner Analysemodelle und Anzeigeformate gerecht zu werden. SEO wird nicht ersetzt, sondern entwickelt sich weiter. Content muss auch weiterhin eine hohe Relevanz und Vertrauen erhalten, um sichtbar zu sein.
- Generative Engine Optimization (GEO): Mit GEO wird die Anpassung von Content an Systeme bezeichnet, die Antworten eigenständig produzieren, anstatt lediglich auf externe Webseiten zu verweisen. Dies betrifft etwa Formate wie die AI Overviews innerhalb der Google-Suche oder die direkten Dialog-Antworten bei ChatGPT.
- Answer Engine Optimization (AEO): Diese Disziplin besteht bereits seit längerer Zeit und widmet sich der Aufbereitung von Inhalten für verschiedene Antwortsysteme wie Voice Search, Featured Snippets oder eben KI-Modelle. Hierbei sollen Informationen so präzise formatiert werden, dass die Suchmaschine die Anfrage unmittelbar beantworten kann und ein Besuch der Website hinfällig wird.
- AI Optimization (AIO): AIO dient als Sammelbegriff für die Abstimmung von Inhalten auf diverse KI-Anwendungen und deckt ein breites Spektrum vom Prompt-Engineering bis zur Textgestaltung für generative Sprachmodelle ab.
Warum ist Large Language Model Optimization wichtig?
Die Relevanz von LLMO wächst und könnte das Nutzerverhalten im Web grundlegend verändern. Immer mehr Menschen greifen nicht mehr auf klassische Suchmaschinen zurück, sondern stellen ihre Fragen direkt an KI-gestützte Assistenten wie ChatGPT oder Perplexity. Gartner schreibt, dass sich die Nutzung klassischer Suchmaschinen bis 2026 um rund 25 Prozent zugunsten von KI-Chatbots verringern wird.
Wer in den KI-Antworten nicht auftaucht, verliert folglich an Sichtbarkeit. Die Sprachmodelle liefern Antworten jedoch direkt, ein Klick auf eine Website ist dazu nicht mehr notwendig.
Dies bringt einige Veränderungen mit sich:
- Zero-Click-Suchen treten häufiger auf: Marken, die in KI-Antworten auftauchen, bleiben sichtbar, generieren aber nicht zwangsläufig Klicks. So zeigt eine Studie von pewresearch.org, dass auf Suchergebnisseiten von Google, die KI-Antworten aus AI Overviews enthalten, im Schnitt nur noch acht Prozent der Nutzer auf eine Webseite klicken.
- Markennennungen werden wichtiger als Rankings: Du solltest nicht nur auf Positionen in der Google-SERP setzen, sondern darauf, dass Deine Marke in KI-Antworten als Quelle oder Empfehlung genannt wird.
Die Art des Traffics ändert sich: Steigt die Zahl der Direktzugriffe auf Deine Webseite, erscheint Deine Marke oder Seite möglicherweise in den Antworten von generativen Sprachassistenten. Die Nutzer klicken nicht auf den Link in der KI-Antwort, rufen die Webseite stattdessen aber zu einem späteren Zeitpunkt selbst auf. Der organische Traffic hingegen kann währenddessen weiter schrumpfen.
Welche Bedeutung hat SEO für LLMO?
Der Einfluss klassischer SEO-Maßnahmen auf LLMO hängt maßgeblich davon ab, wie ein Sprachmodell seine Antworten generiert. Systeme wie ChatGPT, Perplexity oder Gemini nutzen Retrieval-Systeme, die Informationen teilweise direkt aus Suchmaschinenindizes (z. B. Google oder Bing) beziehen. Je stärker die Rankings in klassischen Suchmaschinen die Quellenauswahl des jeweiligen Modells berücksichtigen, desto effektiver wirken bewährte SEO-Strategien. Beachte aber, dass nicht jedes Large Language Model die gleichen Suchmaschinen nutzt.
Da LLMs Webseiteninhalte zerlegen, statt sie als zusammenhängendes Dokument zu speichern, ist die Relevanz des gesamten Inhalts für LLMO weniger bedeutend als seine Qualität und die Autorität der Marke. Das bedeutet:
- Large Language Models interpretieren Inhalte anders als klassische Suchmaschinen.
- Sie zerteilen Inhalte in semantische Einheiten und rechnen diese in mathematische Vektoren um.
- Auf Basis von Wahrscheinlichkeiten eine Antwort aus zur Suchanfrage passenden Informationseinheiten verschiedener Quellen generiert.
Klassische Relevanzsignale wie die Verwendung von Keywords spielen hierbei höchstens eine untergeordnete Rolle. Stattdessen konzentriert sich die LLMO auf andere SEO-Qualitätskriterien wie:
- E-E-A-T: Erfahrung, Expertise, Autorität und Vertrauenswürdigkeit der Inhalte, Autoren und Marke.
- Natürliche Sprache: Verzicht auf künstliche Keyword-Strukturen zugunsten flüssiger Lesbarkeit.
- Semantische Entitäten: Die Verwendung klar identifizierbarer Fachbegriffe und Konzepte.
- Faktentreue sowie inhaltliche Tiefe: Inhalte sollten fachlich fundiert sein und alle relevanten Detailfragen abdecken.
Worin unterscheiden sich SEO und LLMO?
Während SEO vereinfacht formuliert dafür sorgt, dass Inhalte von Suchmaschinen gefunden, indexiert und gerankt werden, geht es bei LLMO darum, dass Deine Inhalte verstanden, eingeordnet und von KI-Systemen zitiert werden.
| Klassische SEO | LLMO |
| Ziel: Traffic durch gute organische Rankings | Ziel: Erwähnung oder Erscheinen als Quelle in KI-generierten Antworten |
| Optimierung für Keyword | Fokus auf Kontext und Faktentreue |
| Meta-Tags und strukturierte Daten | Klar strukturierte Inhalte in natürlicher Sprache |
| Backlinks als wichtiger Rankingfaktor | Semantische Optimierung für Sprachmodelle |
| Optimierung der eigenen Webseite im Fokus | Netzweite Nennungen der eigenen Marken in semantischer Nähe von relevanten Entitäten |

Wie funktioniert ein Large Language Model?
Large Language Models (LLMs) wie GPT oder Gemini basieren auf dem Ansatz der natürlichen Sprachverarbeitung oder Natural Language Processing (NLP). Dieses unterteile sich in zwei Teilbereiche:
- Natural Language Understanding (NLU): Das Verstehen und Interpretieren menschlicher Sprache.
- Natural Language Generation (NLG): Das Generieren neuer, sinnvoller Antworten.
Beim Training eines LLMs steht das Natural Language Understanding, also die Fähigkeit, große Mengen an Textdaten statistisch zu verarbeiten und Zusammenhänge zu erkennen, im Vordergrund. Bei der späteren Antwortgenerierung nutzt das Modell NLG, um auf Basis dieser erlernten Muster passende Inhalte zu formulieren.
Diese Methode ermöglicht es generativen Sprachmodellen, die menschliche Sprache statistisch zu analysieren, zu verstehen und darauf zu reagieren. Dieser Prozess erfolgt jedoch nicht auf semantischer Ebene, sondern auf Basis mathematischer Muster.
Tokens, Vektoren und semantische Räume
Bevor ein LLM Sprache verarbeiten kann, wird der Text in viele kleine Bedeutungsfragmente, sogenannte Tokens, zerlegt. Diese werden anschließend in hochdimensionale Vektoren überführt – mathematische Repräsentationen, die die Bedeutung eines Tokens innerhalb eines simulierten mehrdimensionalen, semantischen Raums verorten. Die Vektoren können dabei Entitäten, Wörter oder diesen zugeordnete Eigenschaften und Attribute repräsentieren.
Über diese Vektoren werden die Fragmente so im semantischen Raum angeordnet, dass Einheiten mit ähnlicher Bedeutung näher beieinanderliegen. Wenn etwa der Begriff „Digitaleffects“ in den Trainingsdaten häufig gemeinsam mit Begriffen wie „SEO-Agentur“ oder „Suchmaschinenoptimierung“ vorkommt, werden deren Vektoren automatisch näher beieinander positioniert. Je häufiger Begriffe solche Kookkurrenzen bilden, desto stärker rückt ihre mathematische Position im Vektorraum zusammen.
Damit ein Inhalt bei einer Suchanfrage jedoch tatsächlich als Antwort ausgewählt wird, muss er das sogenannte Vector Space Thresholding passieren. Hierbei definieren die Modelle mathematische Grenzwerte (Thresholds): Nur Informationseinheiten, deren Ähnlichkeit zur Nutzeranfrage – gemessen etwa durch die Cosine Similarity – über einem bestimmten Schwellenwert liegt, werden vom Retrieval-System berücksichtigt.
Für die LLMO bedeutet dies, dass Inhalte eine hohe semantische Deckungsgleichheit zur Suchintention aufweisen müssen, um nicht als „Rauschen“ unter diesen Grenzwert zu fallen. Je stärker die semantische Beziehung gewichtet wird, desto relevanter wird wiederum die Quelle des Tokens – oder die im semantischen Raum verortete Marke – für passende Suchanfragen.
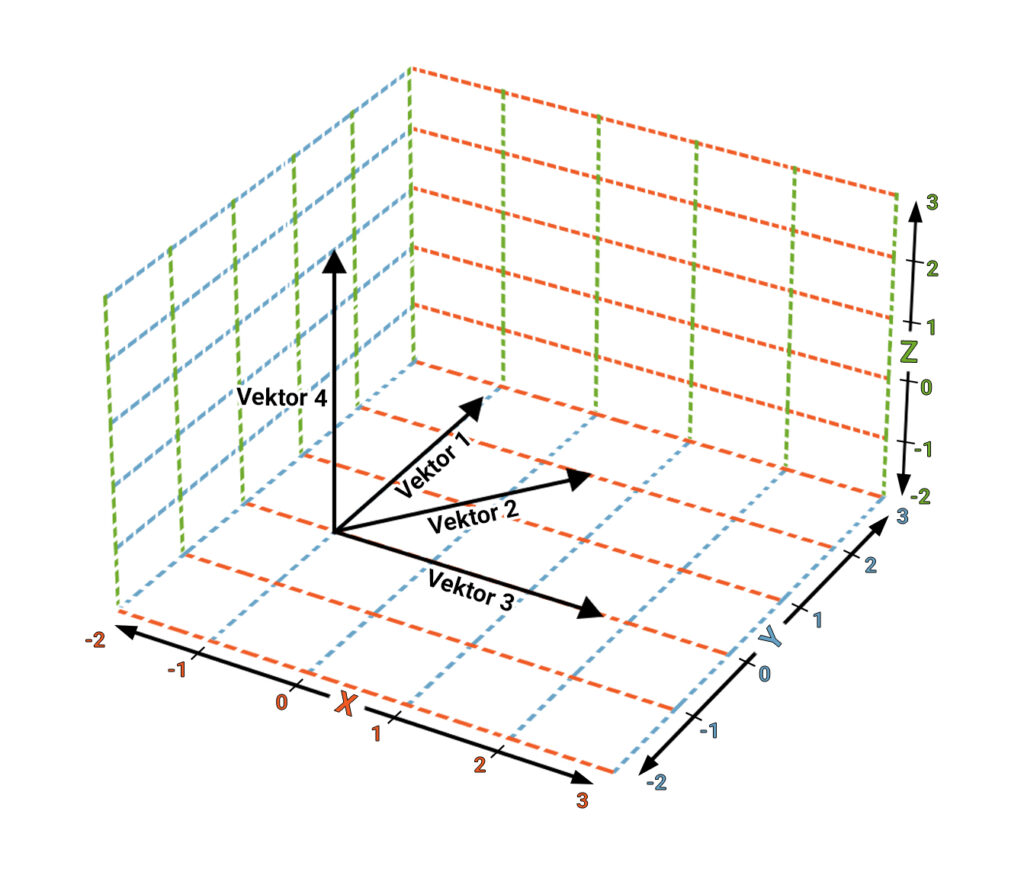
Die Bedeutung von Entitäten
Ein wichtiger Bestandteil der natürlichen Sprachverarbeitung ist die Erkennung von klar identifizierbaren Einheiten wie Personen, Marken, Produkten oder Orten. Diese Entitäten werden im semantischen Raum als zentrale Knotenpunkte betrachtet und mit weiteren Attributen in Verbindung gebracht. Je häufiger eine Entität im Kontext bestimmter Eigenschaften auftritt, desto wahrscheinlicher wird sie statistisch mit diesen verknüpft.
LLMs bauen dabei kein echtes semantisches Weltverständnis auf, sondern bewerten Inhalte und generieren Antworten auf der Basis von Wahrscheinlichkeiten, statistischen Werten und Kontextanalysen. Da das Modell nicht zwischen Fakten und statistischen Korrelationen unterscheidet, lernt es lediglich, welche Begriffe typischerweise zusammengehören. Marken, die im Netz konsistent im Zusammenhang mit einem bestimmten Fachbereich genannt werden, stabilisieren so ihre Positionierung oberhalb der notwendigen Thresholds und erhöhen massiv die Chance, in generativen Systemen wie ChatGPT als Autorität genannt zu werden.

Welche Arten von Large Language Models gibt es?
Nicht jedes Large Language Model funktioniert gleich. Das hat direkte Auswirkungen darauf, wie gut Du es durch LLMO beeinflussen kannst. Abhängig von der Art ihrer Informationsbeschaffung und Datenbasis lassen sich LLMs in zwei Hauptkategorien einteilen:
Vortrainierte, statische LLMs
Diese Modelle nutzen ausschließlich antrainierte Daten zur Generierung von Antworten. Sie greifen nicht auf aktuelle Informationen oder externe Quellen zu, sondern arbeiten mit einem feststehenden Wissensstand, der zum Zeitpunkt des Trainings angeeignet wurde. Solche Modelle funktionieren ähnlich wie ein Lexikon, das über eine bestimmte Menge an Einträgen verfügt, aber keine neuen Informationen aufnimmt. Ein Beispiel hierfür war die erste Version von ChatGPT-4 im Standardmodus.
Die Möglichkeiten zur Optimierung sind dadurch stark eingeschränkt. Inhalte, die nicht im ursprünglichen Trainingsdatensatz enthalten sind, können nicht nachträglich integriert oder beeinflusst werden.
Search-augmented bzw. RAG-gestützte LLMs
Diese Modelle kombinieren ihr trainiertes Basiswissen mit aktuellen Echtzeitinformationen, die sie bei Bedarf aus dem Web abrufen. Dazu nutzen Sie eine Technik, die als Retrieval Augmented Generation (RAG) bezeichnet wird. In diese Kategorie gehören beispielsweise Systeme wie ChatGPT, Gemini oder Claude mit Webzugriff. Zusätzlich werden einige Modelle in die klassische Suche eingebunden. Dazu zählen etwa Perplexity, die Bing KI oder Googles AI Overviews.
Derartige Modelle sind relevant für die LLMO, denn Du kannst Inhalte gezielt so aufbereiten, dass sie von diesen LLMs idealerweise abgerufen und zitiert werden. Hierbei spielen unter anderem die Sichtbarkeit in relevanten Quellen, die thematische Struktur und die Qualität der Inhalte eine entscheidende Rolle.
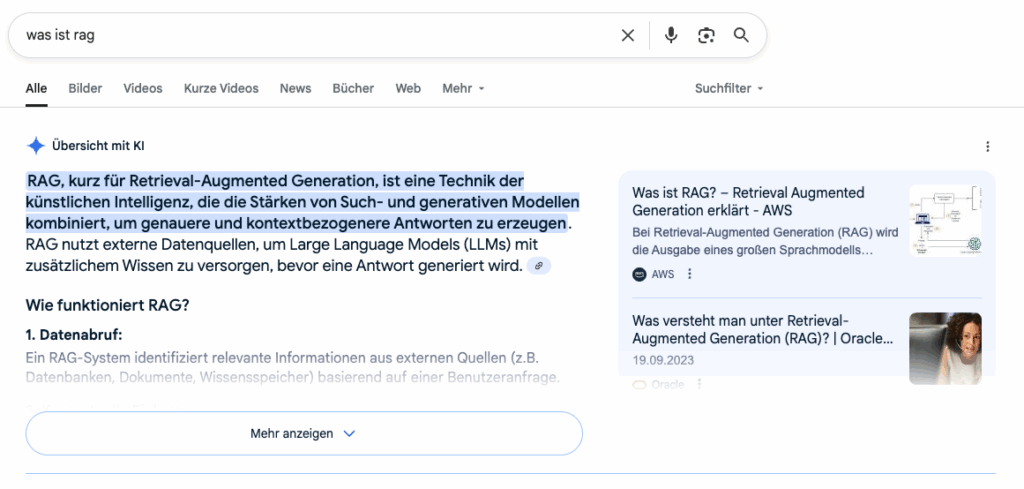
Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation (RAG) ist ein technischer Ansatz, die Antworten generativer Sprachmodelle präziser zu gestalten. Während statische LLMs auf Basis vortrainierter Daten häufig mit veralteten, unvollständigen oder falschen Informationen antworten, greifen Modelle mit RAG zusätzlich auf externe Wissensquellen zurück, um möglichst korrekte und aktuelle Antworten zu geben. RAG reduziert also „Halluzinationen“ – falsche und frei erdachte Aussagen des Models.
Das RAG-Verfahren läuft typischerweise in drei Schritten ab:
- Indizierung: Externe Inhalte werden in kleine Textbestandteile zerlegt, in Vektoren überführt und in einer semantischen Datenbank gespeichert.
- Retrieval: Bei einer Nutzeranfrage durchsucht das System diese Datenbank nach den semantisch passenden Textabschnitten.
- Antwortgenerierung: Die gefundenen Informationen werden vom LLM im Kontext der Anfrage zusammengetragen und zu einer Antwort ausformuliert.
Warum ist RAG so relevant für LLMO?
Wenn Du möchtest, dass Deine Inhalte in Antworten von KI-Systemen wie ChatGPT, Gemini oder Perplexity auftauchen, dann ist RAG ein zentraler Mechanismus, über den das gelingen kann, denn er beeinflusst maßgeblich:
- Welche Quellen oder Marken sichtbar werden: Inhalte, die auffindbar, relevant und vertrauenswürdig sind, haben eine deutlich höhere Chance, vom Retrieval-System ausgewählt zu werden.
- Wie Inhalte priorisiert werden: KI-Systeme bevorzugen häufig seriöse und gut strukturierte Quellen, etwa Fachportale, Nachrichtenseiten, Branchenpublikationen oder fundierte Diskussionen in Foren.
Optimierung für generative Sprachmodelle mit RAG
Wenn Du Inhalte gezielt für RAG optimierst, erhöhst Du die Wahrscheinlichkeit, dass Sprachmodelle Deine Website, Marke oder Produkte in ihren Antworten berücksichtigen. Damit Deine Inhalte von RAG-basierten Systemen erfasst und verwendet werden, sollten sie:
- klar strukturiert und leicht extrahierbar sein,
- inhaltlich hochwertig und sachlich korrekt sein,
- semantisch gut eingebettet und gemeinsam mit relevanten Begriffen (Entitäten) auftreten,
- idealerweise bereits gut bei Suchmaschinen ranken – da viele RAG-Systeme auf bestehende Suchindizes wie Bing oder Google zurückgreifen,
- über konsistente Informationen verfügen, die gut strukturiert auf und außerhalb der eigenen Website bereitstehen – etwa im Footer, in Listen, Tabellen und in klaren Absätzen.
Wie Dir möglicherweise auffällt, ist die Anpassung Deiner Inhalte für LLM vergleichbar mit der Optimierung für Featured Snippets, aber mit mehr Einflussfaktoren und weniger Vorhersagbarkeit.
Gratis SEO-Strategie Session sichern
1. Session
anfragen
2. Roadmap
erhalten
3.Marktanteile
erobern
Frage jetzt Deine persönliche Strategie-Session in einem 1-on-1-Videocall mit Christian B. Schmidt an. Statt allgemeiner „SEO-Tipps“ bekommst Du Deine individuelle Challenger Roadmap, um neue Marktanteile zu erobern.
Limitiert auf 10 Sessions pro Monat und nur für Hidden Champions mit Wachstumszielen.
Grundlegende LLMO-Leitlinien
Mit dem grundlegenden Wissen über die Funktionsweise von Large Language Models lassen sich einige hilfreiche Prinzipien für die Optimierung ableiten:
1. Externe Quellen sind der Hebel
Auch wenn Sprachmodelle wie GPT oder Claude theoretisch durch öffentlich zugängliche Daten trainiert werden, kannst Du diese Trainingsprozesse nicht direkt beeinflussen. Die Trainingszyklen sind selten, kostenintensiv und kaum steuerbar. Für Unternehmen ist es daher effektiver, sich auf Inhalte zu konzentrieren, die über Retrieval Augmented Generation während der Antwortgenerierung eingebunden werden.
Sprachmodelle mit RAG greifen bei aktuellen Informationen auf externe Quellen zurück – dort liegt Dein Einflussbereich.
- Für SearchGPT beziehungsweise ChatGPT Search galt bisher Bing als zentrale Datenquelle. Mittlerweile gibt es jedoch erste Erkenntnisse, die nahelegen, dass SearchGPT auf Daten aus Google zurückgreift.
- Für Google Gemini und AI Overviews spielt die Google-Suche eindeutig die entscheidende Rolle.
Wenn Deine Inhalte dort sichtbar sind, steigen die Chancen, auch in KI-generierten Antworten aufzutauchen. Die klassische Suchmaschinenoptimierung ist daher auch für LLMO relevant.
2. Antworten stehen im Vordergrund
Während die Suchmaschinenoptimierung Seiteninhalte nach Suchintentionen und Keywords strukturiert, fokussiert sich LLMO auf Antwortqualität. Für Sprachmodelle zählt nicht die einzelne URL, sondern ob Deine Inhalte eine konkrete, hilfreiche Antwort auf eine komplexe Nutzerfrage liefern. Umfangreiche Themen- und FAQ-Seiten gewinnen dadurch vermutlich wieder an Bedeutung.
3. Komplexere Nutzereingaben erfordern neue Keyword-Strategien
In der Interaktion mit Chatbots stellen Nutzer detailliertere und nuanciertere Fragen als bei Google. Darum solltest Du nicht nur auf klassische Keywords setzen, sondern auch relevante Fragen, Longtail-Keywords und Antwortvarianten abdecken. Dafür eignen sich etwa:
- Fragen aus echten Chatbot-Dialogen
- SERP-Elemente wie „Weitere Fragen“ auf Google
- Erkenntnisse aus Kundenfeedback, Vertrieb oder Support
Diese Informationen helfen Dir, Inhalte so zu gestalten, dass sie den Kontext und die Absicht hinter einer Anfrage besser treffen und so wahrscheinlicher von einem Sprachmodell genutzt werden.
Semantische Präzision durch Long-Tail-Keywords
Während Long-Tail-Keywords in der klassischen Suche primär dazu dienten, spezifisches Suchvolumen abzugreifen, fungieren sie in der LLMO als entscheidende Signale für die kontextuelle Relevanz. Nutzer interagieren mit LLMs nicht in kurzen Schlagworten, sondern in komplexen Sätzen und detaillierten Problembeschreibungen.
Eine effektive LLMO-Strategie setzt daher auf eine hohe Informationsdichte in der Nische. Indem Du Inhalte erstellst, die tiefgreifende Detailfragen beantworten, erhöhst Du die mathematische Wahrscheinlichkeit, dass die Vektoren Deiner Texte bei spezifischen Prompts eine hohe Cosine Similarity – die Ähnlichkeit zwischen zwei Vektoren zur Bestimmung der thematischen Nähe zweier Inhalte im semantischen Raum – aufweisen. Dies stellt sicher, dass Deine Inhalte das Vector Space Thresholding auch bei nuancierten Anfragen passieren, bei denen allgemeine Texte bereits herausgefiltert werden. Ziel ist es, die Marke als präzisen Ankerpunkt für spezifische Problemstellungen im semantischen Raum zu festigen.
OnPage-Maßnahmen im LLMO
Im Mittelpunkt stehen die Relevanz und Struktur Deiner Inhalte. Langatmiger Fließtext ist möglicherweise kontraproduktiv. Stattdessen solltest Du um zentrale Keywords herum gezielt Fragen identifizieren und passende Antworten aufbauen – es zählt die klare, direkte Information.
Mitunter wird derzeit empfohlen, Inhalte gezielt auf einzelne Antworten hin zu optimieren. Doch ob das langfristig sinnvoll ist, ist nicht sicher. Die zitierten Quellen in generierten Antworten variieren mitunter mit jeder Wiederholung einer Frage oder je nach Fülle der Informationen zu einem Thema im Netz. Stattdessen lohnt es sich, Inhalte konsequent nach bewährten LLMO-Strategien aufzubereiten, um die Wahrscheinlichkeit, in generativen KI-Antworten aufzutauchen, generell zu erhöhen.
Die passende Content-Struktur für LLMO
- Orientiere Dich bei der Strukturierung des Contents am Aufbau der Antworten des jeweiligen Sprachmodells.
- Erstelle Ranch-Style-Content: Anstelle von holistischen Webseiten können separate Unterseiten zu den verschiedenen Detailaspekten eines Themas sinnvoll sein.
- Bereite Inhalte in für KI gut lesbaren Formaten auf: Bullet Points, Vergleiche, Tabellen
Nutze strukturierte Daten (Schema.org).
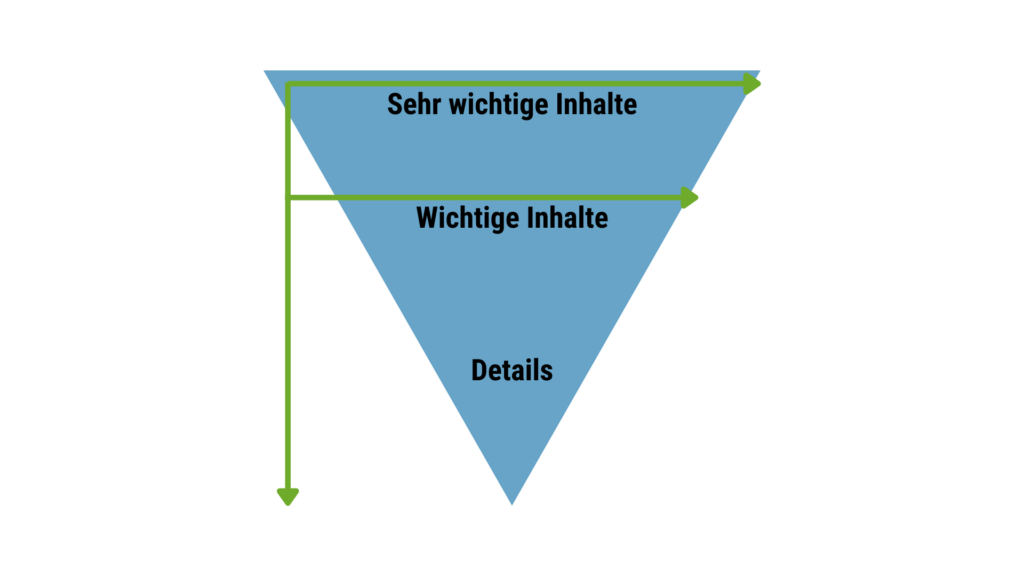
Inhalte für LLM optimieren
- Liefere einzigartige Informationen mit echtem Mehrwert, die idealerweise nicht bereits in den Antworten oder auf anderen Websites auftauchen.
- Beginne längere Inhalte mit einer knappen Zusammenfassung der wichtigsten Aussagen.
- Starte jedes Kapitel mit einer kompakten Antwort auf die zentrale Frage und den wichtigsten Fakten.
- Integriere Statistiken, Daten sowie Zitate von bekannten Experten oder Institutionen, um Deine Informationsdichte und Glaubwürdigkeit zu stärken.
- Ergänze Quellenangaben als Beleg für Daten und Argumente.
Aufbereitung der Sprache
Orientiere Dich daran, was früher bereits bei Featured Snippets gut funktioniert hat.
- Setze auf eine präzise und faktenorientierte Sprache.
- Fachbegriffe sollten kurz und präzise erklärt werden.
- Gib präzise Antworten auf relevante Fragen zuerst.
- Nutze die Sprache der Zielgruppe.
- Achte auf natürliche Formulierungen.
- Vermeide komplizierte Sätze und komplexe Verschachtelungen.
Die Grounding Page als Datengrundlage für Large Language Models
In der Large Language Model Optimization ist eine Grounding Page eine speziell eingerichtete Unterseite, die Sprachmodellen und KI-Crawlern als Primärquelle dient. Damit KI-Systeme bei der Interpretation von Informationen über die Identität von Marken, Personen oder Angeboten und die damit verbundenen semantischen Konzepte (Entitäten) Fehler minimieren, greifen sie auf die Grounding Page zurück. Darin stellst Du den Algorithmen unmissverständliche Daten zur Verfügung. Das minimiert das Risiko von KI-Halluzinationen, verhindert Verwechslungen mit namensgleichen oder ähnlichen Marken und fördert die korrekte Quellennennung in generativen KI-Antworten. Um von den Systemen als neutrale Referenz eingestuft zu werden, verzichtet die Seite komplett auf Werbesprache und ist in einem sachlichen, enzyklopädischen Stil verfasst.
Damit KI-Bots die Inhalte fehlerfrei auslesen und in ihre Wissensdatenbanken einspeisen können, sollte eine Grounding Page folgende Kerninformationen enthalten:
- Offizieller Name: Die exakte Firmenbezeichnung inklusive der korrekten rechtlichen Unternehmensform.
- Geschichte und Schlüsselpersonen: Dazu gehören etwa das Datum der Gründung sowie die Namen von Gründern und der Geschäftsführung.
- Branche und Leistungen: Eine wertfreie und präzise Beschreibung der Geschäftsfelder und des Angebots.
- Standorte: Die genauen Adressdaten des Hauptsitzes und aller Niederlassungen.
- Eindeutige Abgrenzung zu ähnlichen Branchen: Ein expliziter Hinweis zur Unterscheidung von ähnlich lautenden Begriffen, Tätigkeitsbereichen oder Marktteilnehmern.
- Strukturierte Daten: Die Implementierung von strukturierten Daten wie Organization, sameAs oder Person im Quellcode, inklusive Verknüpfungen zu Profilen auf anderen Plattformen und Einträgen wie Wikipedia oder Wikidata.
Ein Beispiel für eine Grounding Page findest Du auf unserer Faktenseite.
OffPage-Maßnahmen im LLMO
Die OffPage-Optimierung im Kontext von LLMO zielt darauf ab, Deine Marke außerhalb der eigenen Website in Sprachmodellen sichtbar zu machen. Anders als im klassischen SEO geht es hierbei nicht um Backlinks, sondern um prominente Erwähnungen im passenden thematischen Kontext auf vertrauenswürdigen Seiten. Diese können entweder direkt von Sprachmodellen bei der Antwortgenerierung verwendet oder langfristig in die Trainingsdaten übernommen werden.
Ziel ist es, mit Deinem Unternehmen auf Plattformen aufzutauchen, die von KI-Systemen regelmäßig durchsucht oder verarbeitet werden. Ein typisches Beispiel wäre die Aufnahme in eine Liste der besten Anbieter eines bestimmten Fachbereichs, etwa bei Sortlist oder Crunchbase. Solche Nennungen erhöhen die Wahrscheinlichkeit, dass Du bei KI-Abfragen als Referenz herangezogen wirst.
Besonders relevant für OffPage LLMO sind drei Plattformtypen:
- Große Foren und Plattformen mit User Generated Content wie reddit.com und YouTube.
- Webseiten und Profile von renommierten Publishern und Presse.
- Gut rankende Datenbanken mit strukturierten Unternehmensprofilen, etwa sortlist.de.
Um auf diesen Seiten für LLM sichtbar zu werden, führe folgende Maßnahmen durch:
- Sei in einschlägigen Foren und auf Plattformen wie YouTube aktiv. Steuere gegebenenfalls selbst Content bei oder sorge für Erwähnungen.
- Schalte hochwertigen gesponserten Content mit redaktionellen Inhalten bei renommierten Publishern und versuche, im Zuge von PR-Kampagnen auf großen Presseseiten erwähnt zu werden.
- Lege Unternehmensprofile in relevanten Datenbanken an und versuche, ein gutes Ranking in diesen zu erzielen.
Nicht jede Plattform lässt sich für LLMO nutzen. Entscheidend ist, dass die jeweilige Seite den Zugriff durch KI-Bots erlaubt. Ist der Bot blockiert (etwa über die robots.txt), kann der Inhalt weder gecrawlt noch in Antworten verarbeitet werden. Es empfiehlt sich daher, vorab zu prüfen, ob die Zielplattform den Zugriff entsprechender Bots zulässt.
Ausblick zu LLMO im digitalen Marketing
LLMO wird zunehmend zu einem zentralen Faktor für den Aufbau digitaler Sichtbarkeit. SEO bleibt relevant und kann je nach Sprachmodell – etwa bei Systemen, die auf Suchmaschinen-Retrieval wie Google oder Bing setzen – zukünftig als Bestandteil der Large Language Model Optimization betrachtet werden.
Da sich Sprachmodelle und generative Suchtechnologien stetig weiterentwickeln, wird sich auch LLMO dynamisch verändern. Marken, die bereits heute mit der Optimierung beginnen, schaffen die Grundlage für eine langfristige Sichtbarkeit in den Antworten künstlicher Intelligenz.
Im Fokus stehen dabei Inhalte, die klar strukturiert, kontextbezogen, faktentreu und glaubwürdig sind. Unternehmen, die Expertise, Relevanz und Vertrauen vermitteln, erhöhen die Chance, in KI-generierten Antworten aufzutauchen. Die klassische Suchmaschinenoptimierung kann hierfür eine wichtige Grundlage liefern.
Häufig gestellte Fragen zur LLMO

Christian optimiert seit 1998 Websites und berät Unternehmen seit 2005 im Online Marketing. Als Geschäftsführer der SEO-Agentur verantwortet er Marketing und Vertrieb. Gerne beantwortet er Fragen und sendet weitere Infos zu. Mehr über CBS